iHuman Android API 请求sign计算方法
本文主要讨论API请求sign计算方法
背景
iHuman Android APP 里面有一些音频资源,直接抓包就可以拿到请求参数,然后直接可以用来请求资源。
由于timestamp没有检验,抓到的请求参数在登录信息没有变更的情况下应该是可以一直使用的,
但是如果你在登录的设备上重新登录或者登录其它账号,那么之前的请求参数就不可用了,需要重新抓包。
Example
{
'uid': '123456',
'app_version': '4.1.0',
'sign': '02049776b9faba39d375e2a44ewgwkqw288sf3sfa6ab16875063d49ad9f0ed494'
'device': 'phone',
'deviceid': '403d8d2wqf32453tre6t34t345yt4ec03a',
'platform': 'Android',
'token': '00MYUISKWU923kjsdfuih3CFzwaw9ku5OAElVvvOg=',
'timestamp': '1611029052'
}
先看一下主要的参数
uid: 就是用户的唯一IDapp_version: 使用app版本,sign: 就是使用其它的某些参数,通过一定的加密算法得到的,下面主要讲如何计算该签名device: 好像是固定的phone.deviceid: 每一台设备都会有一个唯一的ID,platform: 我的是Android,token: 应该是服务器签发给客户的一个凭证,timestamp: 就是时间戳
目标
就是通过计算得到签名来减少由于登录问题引起的每次都要抓包。如果我们可以通过计算得到签名或者就可以不用每次抓包了。
分析
想要知道API请求是如何计算签名的,我们需要分析APP的内部代码才行,凭空猜想是不行,现在app一般都会混淆,加壳。。。
最新版本的APP在反逆向方面做的更加完善,为了更容易的得到我们想要的,我建议把之前一些版本也一并分析,可能会简单些, 这个APP就是
- 使用到工具有很多: dex2jar, jd-gui, JEB, frida, frida-server, frida-dexdump...
- 首先从网络上下载一些版本安装包(目前我使用的主要版本:2.0.1, 2.1.0, 3.2.1, 4.1.0)
- 不同的版本混淆和加壳也是不一样,随着技术的更新,加壳的方式也不同,脱壳的技术也在更新。具体问题具体分析
- 通过使用上面提到的一些工具,得到我们想要的一些DEX, 接下来就是该分析代码了,
看代码
这是一个比较痛苦的过程,因为大部分代码都已经通过混淆,已经无法知道它们原来的名字,都变成了a,b,c,d,f等这样的名称,完全不知道什么意义,
本来熟悉一下正常的项目都需要花费一些时间,更新何况经过了混淆,但只要静下心来,从一些关键点着手还是能找到一些蛛丝马迹的,还是有希望的
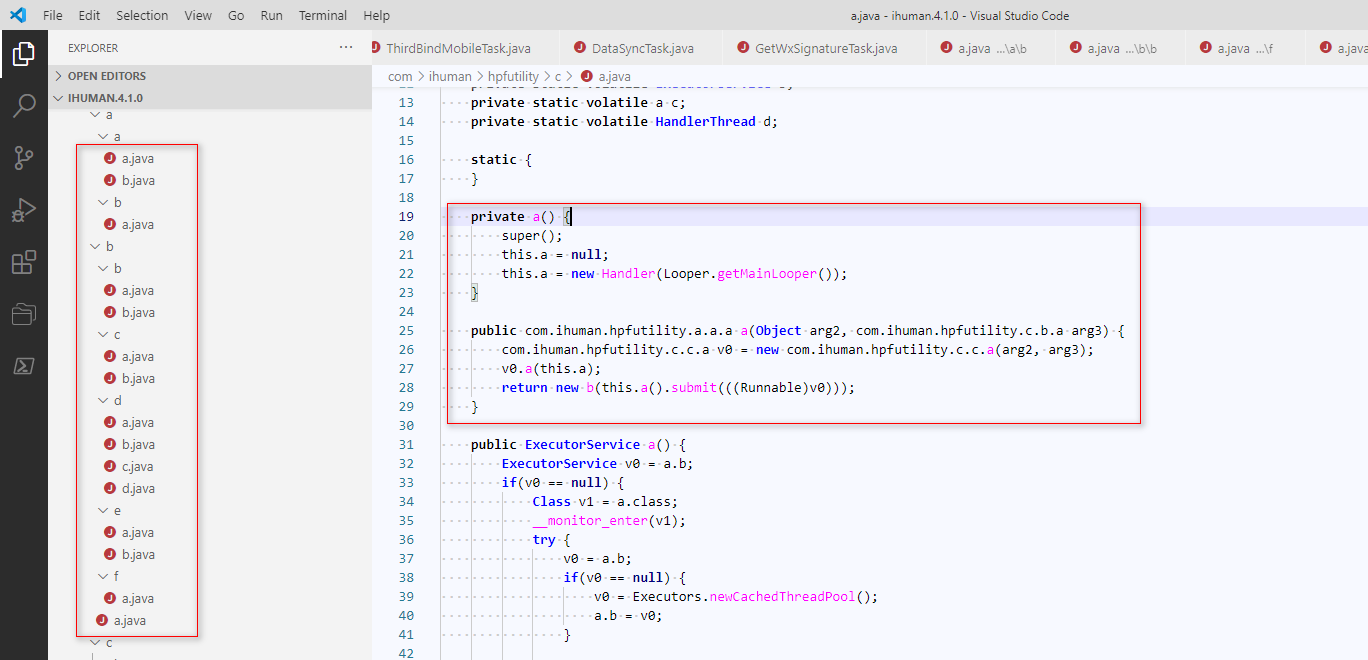
从2.0.1的源代码中我们找到了com\ihuman\hpfutility\net\d\c.java中重要的方法 ia()
在4.1.0中也有相同的方法,只是还原出来并不是很好理解
version: 2.0.1
public HashMap<String, String> ia() {
Field[] declaredFields;
Pair pair;
HashMap<String, String> hashMap = new HashMap<>();
int id = id();
ArrayList arrayList = new ArrayList();
ArrayList<Pair> arrayList2 = new ArrayList<>();
Class cls = getClass();
while (true) {
Class cls2 = cls;
for (Field field : cls2.getDeclaredFields()) {
if (((Expose) field.getAnnotation(Expose.class)) != null) {
SignId signId = (SignId) field.getAnnotation(SignId.class);
SignParam signParam = (SignParam) field.getAnnotation(SignParam.class);
boolean z = !(signId == null || (signId.value() & id) == 0) || (signParam != null && signParam.hV());
field.getType().getName();
SerializedName serializedName = (SerializedName) field.getAnnotation(SerializedName.class);
String str = serializedName != null ? serializedName.value() : field.getName();
field.setAccessible(true);
try {
if (((ExcludeParamIfEmpty) field.getAnnotation(ExcludeParamIfEmpty.class)) == null) {
pair = new Pair(str, field.get(this));
} else {
Object obj = field.get(this);
boolean z2 = true;
if (obj == null) {
z2 = false;
} else if (obj instanceof Number) {
z2 = ((Number) obj).longValue() != 0;
} else if (obj instanceof String) {
z2 = !TextUtils.isEmpty((String) obj);
}
if (z2) {
pair = new Pair(str, obj);
}
pair = null;
}
} catch (IllegalAccessException e) {
ThrowableExtension.printStackTrace(e);
}
if (pair != null) {
arrayList2.add(pair);
if (z) {
arrayList.add(pair);
}
}
}
}
cls = cls2.getSuperclass();
if (cls == null) {
break;
}
}
for (Pair pair2 : arrayList2) {
hashMap.put(pair2.first, pair2.second == null ? "" : pair2.second.toString());
}
String ao = com.ihuman.hpfutility.net.f.a.ao(b(arrayList, false));
if (ao == null) {
throw new IllegalArgumentException("Sign data error !");
}
hashMap.put(HwPayConstant.KEY_SIGN, ao);
return hashMap;
}
上面这段代码比较好理解,就是遍历当前类(及父类)中所有声明的字段, 把这些字段通过一些判断把它们添加到arrayList2
如果某些字段通过计算是签名的字段就再把它们添加另一个arrayList中,关键点在于字段上是否注释SignId及SignId.value,或者是否有注释signParam
SignId.value还与id()方法做&运算,在4.1.0中变为了i(), 每个子类中的i()/id()中的值也完全不同,参与计算签名的字段也不同,得到的结果也不同
version:2.0.1
private String b(List<Pair<String, ? extends Object>> list, boolean z) {
Collections.sort(list, new a());
StringBuilder sb = new StringBuilder();
int size = list.size();
for (int i = 0; i < size; i++) {
Pair pair = (Pair) list.get(i);
if (i != 0) {
sb.append(HttpUtils.PARAMETERS_SEPARATOR);
}
sb.append((String) pair.first).append(HttpUtils.EQUAL_SIGN).append(z ? com.ihuman.hpfutility.common.b.a.URLEncode(pair.second.toString()) : pair.second);
}
return sb.toString();
}
这个方法就是要把计算签名的参数列表拼成key=value的字符串,为后面的加密做准备, Example: a=1&b=2&c=3
接着我们找到加密算法com.ihuman.hpfutility.net.f.a.ao
version: 2.0.1
public class a {
private static final char[] Cd = {'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f'};
public static String ao(String str) {
String ap = ap(str);
if (ap != null) {
return aq(ap);
}
return null;
}
public static String ap(String str) {
byte[] digest;
try {
byte[] bytes = str.getBytes();
MessageDigest instance = MessageDigest.getInstance("MD5");
instance.update(bytes);
char[] cArr = new char[(r4 * 2)];
int i = 0;
for (byte b : instance.digest()) {
int i2 = i + 1;
cArr[i] = (char) Cd[(b >>> 4) & 15];
i = i2 + 1;
cArr[i2] = (char) Cd[b & dm.m];
}
return new String(cArr);
} catch (Exception e) {
ThrowableExtension.printStackTrace(e);
return null;
}
}
public static String aq(String str) {
return k(str, "SHA-256");
}
private static String k(String str, String str2) {
if (str == null || str.length() <= 0) {
return null;
}
try {
MessageDigest instance = MessageDigest.getInstance(str2);
instance.update(str.getBytes());
byte[] digest = instance.digest();
StringBuffer stringBuffer = new StringBuffer();
for (byte b : digest) {
String hexString = Integer.toHexString(b & 255);
if (hexString.length() == 1) {
stringBuffer.append('0');
}
stringBuffer.append(hexString);
}
return stringBuffer.toString();
} catch (NoSuchAlgorithmException e) {
ThrowableExtension.printStackTrace(e);
return null;
}
}
}
这个加密算法也不是很难,原字符串取MD5摘要,遍历摘要无符号右移4位再与15做&运算,然后做为索引取字符数组Cd的值,
接着不右移直接与15做&运算,做索引取字符数组Cd的值, 把所有的从Cd数组中得到的字符再拼成一个字符串,
然后再这个字符串[调用aq方法]进行SHA256加密,得到的结果就是sign字符串,也是我们最终想要的结果
总结
在4.1.0中主要参与计算签名的字段和基类i()方法返回10
@Expose @SerializedName(value="uid") @ExcludeParamIfEmpty @SignId(value=1) private String e;
@Expose @SerializedName(value="deviceid") @ExcludeParamIfEmpty @SignId(value=2) private String f;
@Expose @SerializedName(value="token") @ExcludeParamIfEmpty @SignId(value=16) private String g;
@Expose @SerializedName(value="timestamp") @ExcludeParamIfEmpty @SignId(value=8) private long h;
//基类
public int i() {
return 10;
}
//子类 com.ihuman.story.datasource.remote.request.c
//https://storyapi.ihuman.com/v2/daily_checkin
public int i() {
return super.i() | 1 | 16; //27
}
//子类 com.ihuman.story.datasource.remote.request.a
//https://storyapi.ihuman.com/recommend
public int i() {
return 8;
}
//子类 com.ihuman.story.datasource.remote.request.z0
//https://storyapi.ihuman.com/login
public int i() {
return 15;
}
从上面代码分析我们大概得到一张表
| Field | value | 8 | 10 | 15 | 27 |
|---|---|---|---|---|---|
| uid | 1 | ✘ | ✘ | ✔ | ✔ |
| deviced | 2 | ✘ | ✔ | ✔ | ✔ |
| timestamp | 8 | ✔ | ✔ | ✔ | ✔ |
| token | 16 | ✘ | ✘ | ✘ | ✔ |
这样我们就很容易知道哪些API需要参与计算签名的字段了,
至此所有的分析都完成了, [手动撒花~]
Python3完整代码实现
#!/usr/bin/env python3
# _*_ coding: utf-8 _*_
import json
import os
import time
import re
import sys, getopt
import hashlib
import requests
import random
from collections import OrderedDict
#无符号右移
import ctypes
def int_overflow(val):
maxint = 2147483647
if not -maxint-1 <= val <= maxint:
val = (val + (maxint + 1)) % (2 * (maxint + 1)) - maxint - 1
return val
def unsigned_right_shitf(n,i):
# 数字小于0,则转为32位无符号uint
if n<0:
n = ctypes.c_uint32(n).value
# 正常位移位数是为正数,但是为了兼容js之类的,负数就右移变成左移好了
if i<0:
return -int_overflow(n << abs(i))
#print(n)
return int_overflow(n >> i)
def get_sign(data):
src = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f']
ordered_data = OrderedDict(sorted(data.items()))
ordered_data_str = '&'.join([f"{k}={ordered_data[k]}" for k in ordered_data.keys()])
print(ordered_data_str)
digest = hashlib.md5(f'{ordered_data_str}'.encode('utf-8')).digest()
r = []
for d in digest:
i = unsigned_right_shitf(d, 4) & 15
r.append(src[i])
r.append(src[d & 15])
m5 = ''.join(r)
print(m5)
s256 = str(hashlib.sha256(m5.encode('utf-8')).hexdigest())
return s256
if __name__ == "__main__":
param = {
'uid': 'uid',
'deviceid': 'deviceid',
'token': 'token',
'timestamp': 'timestamp'
}
print(get_sign(param))

还没有人评论,抢个沙发吧...